













.webp)
July 3, 2026
|
5 min read

Published: February 13, 2026

Blazingly fast way to build, track and deploy your models!
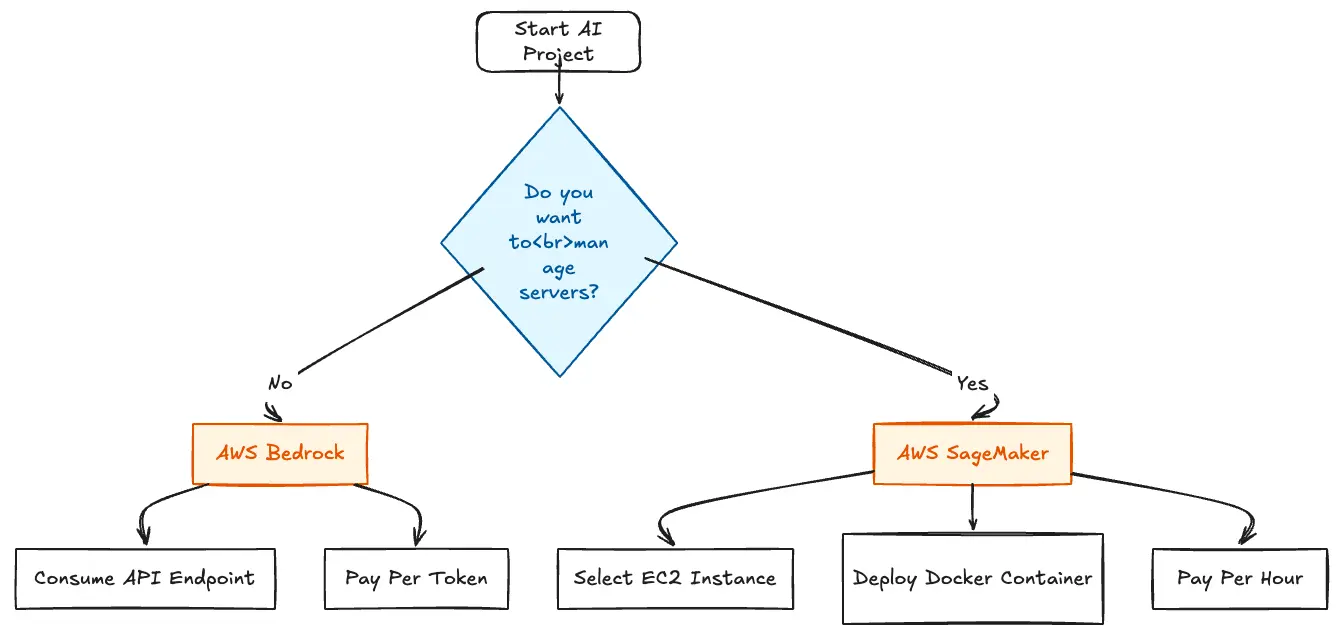
For teams building Generative AI on AWS, the choice often narrows down to two contenders: AWS Bedrock and AWS SageMaker. AWS positions Bedrock as the streamlined path for building, while SageMaker is positioned as the comprehensive service for deep control.
But the difference isn't merely about ease of use; it is a fundamental architectural fork in the road between consuming APIs and owning infrastructure. Choosing the wrong path can lead to unpredictable token costs on one side or significant operational overhead on the other.
This guide explores the critical differences, the hidden trade-offs of each, and why a third option like TrueFoundry is emerging as the preferred choice for scaling enterprises that want the best of both worlds.
At the heart of this comparison is how each service treats compute and ownership. You are effectively choosing between buying electricity from the grid (Bedrock) or renting a generator to produce it yourself (SageMaker).
Bedrock operates on a purely serverless model that abstracts away the underlying hardware entirely. This allows you to consume AI strictly as a utility without ever managing servers, instances, or containers. Instead of hunting for model weights or worrying about GPU drivers, you simply select high-performance models - like Anthropic Claude, Meta Llama, or Amazon Titan - from a curated, managed menu. Because there is no "cold start" for infrastructure, these models are instantly available, allowing you to pay strictly for the tokens processed rather than for idle server time.
SageMaker is fundamentally an infrastructure-as-a-service play where you rent raw compute power. Unlike Bedrock, you must actively select specific EC2 instance types (e.g., ml.g5.2xlarge), deploy your own Docker containers, and manually manage the endpoints. While this grants you full control over the environment, it also burdens you with operational responsibilities like defining auto-scaling policies, handling security patching, and managing the server lifecycle. Crucially, the economics differ significantly: you pay for every second the instance is running, regardless of whether it is processing requests or sitting idle.
Bedrock is designed for speed and simplicity. It is the ideal starting point for most GenAI applications where "time-to-market" is the primary KPI.
If your goal is rapid prototyping - such as building a chat demo, a RAG (Retrieval-Augmented Generation) bot, or an internal copilot within a tight two-week sprint - Bedrock allows you to bypass the heavy lifting of infrastructure setup completely. It is also the only path if you require access to proprietary models like Anthropic Claude, as these are not available as open weights for hosting on SageMaker. Furthermore, Bedrock is superior for handling variable traffic patterns. For internal tools or new products where usage is "spiky," your costs drop to zero the moment users stop interacting with the app, preventing waste during nights and weekends.
SageMaker is built for control and customization. It shines when you hit the limitations of a managed API or need to manipulate the model internals.
Teams engaging in deep fine-tuning workloads generally prefer SageMaker. While Bedrock offers lightweight adapters, SageMaker allows for full parameter updates, which is essential for complex training pipelines or RLHF (Reinforcement Learning from Human Feedback). It is also the necessary choice for custom or niche open-source models; if you need a specific version of a coding model or an uncensored LLM not found on Bedrock's menu, SageMaker allows you to wrap any model in a Docker container and run it. Finally, SageMaker is often required by regulated industries (like defense or banking) that demand strict data isolation, as it allows models to run inside a private VPC without ever traversing a shared service endpoint.
For organizations navigating these complex legal and ethical requirements, our guide on AI compliance provides a foundational roadmap for maintaining accountability at scale.
Both platforms introduce additional costs and friction points that typically appear only after you scale beyond the initial prototype.
Pricing estimates based on AWS Bedrock Pricing for Provisioned Throughput (US East N. Virginia) as of Jan 2026. High-performance models (e.g., Anthropic Claude V2/3) typically require the purchase of Model Units (MUs). One MU is often priced between $20–$30 per hour depending on the specific model and contract term (1-month vs. 6-month). Math: $30/hour × 24 hours × 30 days = $21,600 per month for a single Model Unit. Production workloads requiring redundancy or higher rate limits often require 2+ MUs, effectively doubling this cost.
SageMaker deployments can be complex to debug due to distributed logging. Teams often face visibility challenges when endpoints fail without clear error messages. Resolving these errors often requires deep, AWS-specific expertise. Consequently, many teams find they need to hire dedicated MLOps engineers just to keep their SageMaker pipelines healthy, which diverts significant budget away from actual model development and innovation.
To eliminate this lack of visibility and gain real-time insights into model performance, teams should implement centralized observability in AI Gateway to track every interaction and prevent failure before it happens.
As usage grows, cost patterns diverge sharply. Bedrock costs scale linearly with volume... SageMaker becomes more cost-efficient at high volume - if you can manage it.
Table 1: Cost Structure Comparison
As usage grows, Bedrock penalizes high volume with linear scaling, while SageMaker rewards high volume with utilization efficiency, if you can manage it. For a more granular breakdown of exactly how instance markups and hidden storage fees inflate your monthly bill, see our deep dive on SageMaker pricing.
Some organizations adopt both services hoping to balance these trade-offs, but this often leads to increased organizational complexity rather than optimization.
Teams often end up using Bedrock for inference (the application layer) and SageMaker for training (the data science layer). This creates a fragmented workflow with two separate silos of code, two deployment pipelines, and two different sets of security protocols.
As a result, billing becomes scattered across "Model Inference" (Bedrock), "Compute Instances" (SageMaker), "Storage" (EBS), and "Monitoring" (CloudWatch), making it nearly impossible for finance teams to calculate the true ROI or "Cost Per Transaction" of a single AI feature.
The key to resolving this friction is achieving true AI interoperability, allowing your team to switch between providers and architectures without rebuilding your entire infrastructure.
TrueFoundry offers a "middle path" between Bedrock’s simplicity and SageMaker’s control. It abstracts the complexity of infrastructure while keeping costs low by leveraging raw compute.
TrueFoundry lets you deploy any open-source or custom model - such as Llama 3, Mistral, or Qwen - directly inside your AWS account without the vendor restrictions associated with Bedrock’s curated list. You are not limited to a curated list of vendors, giving you the freedom to experiment with the latest open-source innovations the day they are released.
This ensures you retain full ownership of your model weights and infrastructure, preventing lock-in to any specific API provider's roadmap.
The platform is designed to give you a "Bedrock-like" experience on your own infrastructure. Teams can switch between models using simple configuration changes rather than rewriting complex SageMaker deployment scripts or managing Dockerfiles.
It effectively provides an "AI Gateway" experience that handles the operational friction, making deployment fast and intuitive for application engineers, not just cloud architects.
This is the most significant differentiator for scaling teams. TrueFoundry lowers costs through two mechanisms:
Removing the Markup: Unlike SageMaker, which often adds a premium to the underlying compute cost, TrueFoundry allows you to pay raw AWS EC2 rates.
Spot Instance Orchestration: The platform automatically orchestrates inference on AWS Spot Instances (spare capacity). Because Spot instances are typically priced 60–90% lower than On-Demand instances, TrueFoundry creates a massive arbitrage opportunity.
By managing the failover between cheap Spot instances and reliable On-Demand instances, TrueFoundry captures these savings—reducing total compute costs by up to 60% compared to standard SageMaker deployments—without sacrificing reliability.
TrueFoundry Cost Efficiency Model
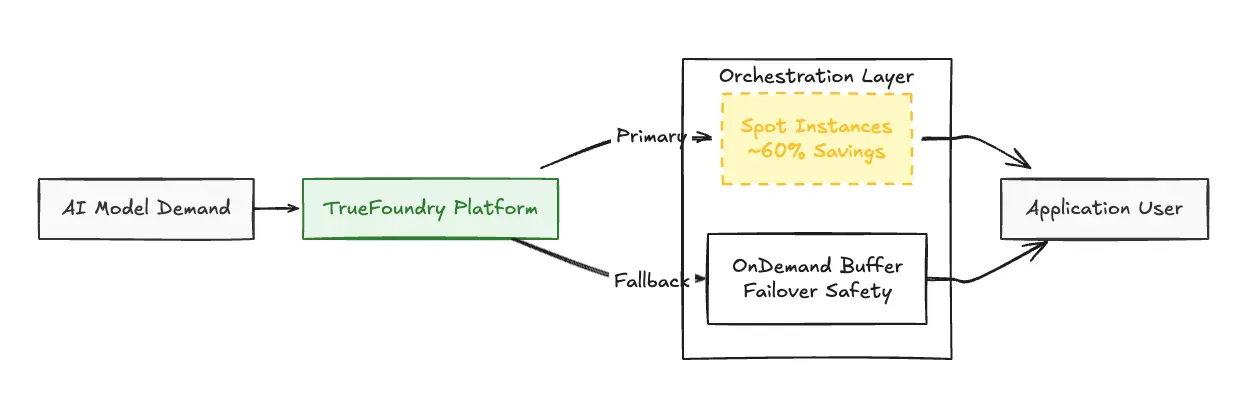
Note: Cost savings estimates are based on standard AWS pricing comparing SageMaker On-Demand instances to EC2 Spot instances. Actual savings depend on AWS Spot market availability in your selected region.
TrueFoundry abstracts the complexity of infrastructure management while keeping costs low by leveraging raw compute inside your own account. This architecture not only reduces spend but is also a core component of geopatriation, ensuring your data remains within sovereign borders to comply with regional residency laws.
Table 2: Feature and Capability Comparison
AWS SageMaker and AWS Bedrock both solve important problems, but neither fits every stage of growth perfectly.
While AWS provides the raw materials for AI, TrueFoundry provides the engine to run them efficiently. If you're ready to stop choosing between 'DevOps Fatigue' and 'Token Bill Shock,' book a demo with TrueFoundry today and see how we can optimize your AWS AI infrastructure for scale.
The main difference is architecture: AWS Bedrock is a serverless API service where you pay per token to use pre-trained models. AWS SageMaker is an infrastructure service where you rent servers (instances) to host and train your own models.
The main reason to use SageMaker is control. It allows you to use custom models that aren't available on Bedrock, perform deep fine-tuning, and run workloads inside a fully isolated private network (VPC).
Bedrock fine-tuning is a managed, "lightweight" process mostly used for adapting model style or tone (PEFT), and it supports a limited set of models. SageMaker fine-tuning is a "heavyweight" process that allows full parameter updates, custom training scripts, and deep modifications to any model architecture.
TrueFoundry provides the ease of use of Bedrock with the flexibility of SageMaker, but at a much lower cost. It enables you to run models on Spot Instances (saving ~60%), eliminates vendor lock-in, and provides a unified "AI Gateway" that works across multiple providers.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




